这是一本关于JavaScript性能的书。
###第一章 加载和执行
关于脚本位置,大家应该都知道,将JavaScript脚本放在底部1
2
3 <script>JavaScript Code</script>
</body>
</html>
这也是雅虎特别小组提出的优化JavaScript的首要规则。
复杂的Web应用可能需要依赖数个JavaScript文件,可以把多个JavaScript文件合并成一个,这样只需要引用一个<script>标签,就可以减少性消耗。文件合并的工作可以交给打包工具。
更高端点的就是无阻塞的脚本,推荐的无阻塞模式是先添加动态加载所需的代码,然后加载初始化页面所需的剩下的代码。因为第一部分的代码尽量精简,甚至只可能只包含loadScript()函数,它下载和执行都是极快的,对页面基本无影响,一旦初始代码就位,就用它来加载剩余的JavaScript文件,例如:1
2
3
4
5
6<script type="text/javascript" src="loader.js"></script>
<script type="text/javascript">
loadScript("the-rest.js", function () {
Applocation.init();
});
</script>
把这段代码放到</body>标签之前,大约有以下几个好处:
- ####这样做确保了JavaScript执行的过程中不会阻碍页面其他内容的显示
- ####当第二个JavaScript文件下载完成时,应用所需的所有DOM结构已经创建完毕,并做好了交互的准备,从而避免了类似window.onload事件来检测页面是否准备好。
还可以把loadScript()函数直接嵌入页面,从而避免多产生一次HTTP请求(loader.js)
一旦页面初始化所需的代码完成下载,你就可以继续自由的使用loadScript()去加载页面其他的功能所需的脚本。了解更多可以搜索 YUI3的yui-min.js Lazyload类库 LABjs
###第二章 数据访问
每一种数据存储的位置都有不同的读写消耗,大多数情况下,从一个直接量和一个局部变量中存取数据的性能差异是微不足道的。访问数组元素的对象成员的代价则高一些,具体高出多少则取决于浏览器。
函数中读写局部变量总是最快的,而读写全局变量通常是最慢的。因为全局变量总是存在于运行期上下文作用域链的最末端,因此也是最远的。
属性或方法在原型链中的位置越深,访问它的速度也越慢。
通常来说,把常用的对象成员、数组元素、跨域变量保存在局部变量中来改善JavaScript性能
###第三章 DOM编程
####天生就慢
简单理解,两个相互独立的功能只要通过接口彼此连接,就会产生消耗。有个贴切的比喻 ,把DOM和JavaScript(这里只ECMAScript)各自比喻成一个岛屿,它们之间用收费桥梁来连接,因此访问DOM的次数越多,费用也就越高,显而易见的是要减少“过桥”的次数,努力呆在ECMAScript岛上。
访问DOM元素是有代价的,修改元素的代价更昂贵,因为它会导致浏览器重新计算页面的几何变化,重绘页面。举个简单的例子:1
2
3
4
5function innerHTMLLoop () {
for (var count = 0; count < 10000; count++) {
document.getElementById('here').innerHTML += "a";
};
}
这个函数循环修改页面元素的内容,但有个严重的问题在于每次循环迭代,该元素都会访问两次,一次读取innerHTML属性值,一次重写它,再看优化后的例子:1
2
3
4
5
6
7function innerHTMLLoop2 () {
var content = "";
for (var count = 0; count < 10000; count++) {
content += "a";
};
document.getElementById('here').innerHTML += content;
}
所有浏览器中,优化后的版本都运行的更快,结果充分表明,访问DOM的次数越多,代码的运行速度越慢。因此,一般的经验法则是:减少访问DOM的次数,把运算尽量留在ECMAScript这一端处理。
修改页面区域的最佳方案是用非标准但支持良好的innerHTML属性呢还是只用类似document.createElement()的原生DOM方法?若不考虑Web标准,两者性能相差无几,但是在除开最新版本的WebKit内核(Chrome和Safari)之外的所有浏览器中,innerHTML会更快一些,所以还是试用innerHTML吧!
####HTML集合
HTML集合是包含了DOM节点引用的类数组对象,通常有以下三种:
- ####
document.getElementsByTagName(); - ####
document.getElementsByName(); - ####
document.getElementsByClassName();
不要问为什么document.getElementById()不是类数组对象。
还有另外四个不常用的:
- ####
document.images页面中所有img元素 - ####
document.links页面中所有a元素 - ####
document.forms页面中所有表单元素 - ####
document.forms[0].elements;页面中第一个表单的所有字段
以上方法和属性的返回值为HTML集合对象,这是个类似数组的列表。它们并不是真正的数组(因为没有push()和slice()之类的方法),但提供了一个类似数组中的length属性,并且还能像数组一样以数字索引的方式访问列表中的元素。
下面这个例子是把页面中的div元素数量翻倍吗?1
2
3
4var allDivs = document.getElementsByTagName('div');
for (var i = 0; i < allDivs.length; i++) {
document.body.appendChild(document.createElement('div'));
};
呵呵!好像不是,这是一个意外的死循环,因为循环的退出条件allDivs.length在每次迭代时都会增加,它反映出的是底层文档的当前状态。事实上,HTML集合一直与文档保持着连接,每次你需要最新的信息时,都会重复执行查询的过程,哪怕只是获取集合里元素的个数也是如此,这正是低效之源。
在循环的条件控制语句中读取数组的length属性是不推荐的做法,读取一个集合的length属性要比普通数组的length属性要慢得多,因为每次都要重新查询。
####选择器API
对DOM中的特定元素操作时,通常使用document.getElementsByTagName()和document.getElementsById(),有时为了得到需要的元素列表,还需要组合调用它们并遍历返回的节点,但这种繁密的过程效率低下。最新的浏览器提供了querySelector()和querySelectorAll()的原生DOM方法(目前 IE8及Firefox/Chrome/Safari/Opera 的最新版已经支持它们),这种方式自然比使用JavaScript和DOM来遍历查找元素要快的多。考虑如下代码:1
var elements = document.querySelectorAll('#parent a');
elements的值包含一个引用列表,指向位于id="parent"的元素之中的所有a元素,querySelectorAll()方法是用CSS选择器作为参数并返回一个NodeList——包含着匹配节点的类数组对象,这个方法不会返回HTML集合,因此返回的节点不会对应实时的文档结构,因此这也避免了之前讨论的HTML集合引起的性能(和潜在逻辑)问题,如果不使用querySelectorAll(),为了达到相同的目的,应该这样写:1
var elements = document.getElementById('parent').getElementsByTagName('a');
这种情况下elements会是一个HTML集合,所以你还要把他们拷贝到数组中,才能得到与querySelectorAll()返回值类似的静态列表(IE8会alert出StaticNodeList)。
因此如果要处理大量组合查询,使用querySelectorAll()的话会更有效率。
####重绘和重排
当浏览器下载完所有页面 HTML 标记,JavaScript,CSS,图片之后,它解析文件并创建两个内部数据结构:
- ####DOM树 表示页面结构
- ####渲染树 表示 DOM 节点如何显示
渲染树中为每个需要显示的 DOM 树节点存放至少一个节点(隐藏 DOM 元素在渲染树中没有对应节点)。渲染树上的节点称为“框”或者“盒”,符合 CSS 模型的定义,将页面元素看作一个具有填充、边距、边框和位置的盒。一旦 DOM 树和渲染树构造完毕,浏览器就可以显示(绘制)页面上的元素了。
当 DOM 改变影响到元素的几何属性(宽和高)——例如改变了边框宽度或在段落中添加文字,将发生一系列后续动作——浏览器需要重新计算元素的几何属性,而且其他元素的几何属性和位置也会因此改变受到影响。浏览器使渲染树上受到影响的部分失效,然后重构渲染树。这个过程被称作重排版。重排版完成时,浏览器在一个重绘进程中重新绘制屏幕上受影响的部分。
不是所有的 DOM 改变都会影响几何属性。例如,改变一个元素的背景颜色不会影响它的宽度或高度。在这种情况下,只需要重绘(不需要重排版),因为元素的布局没有改变。
重绘和重排版是负担很重的操作,可能导致网页应用的用户界面失去相应。所以,十分有必要尽可能减少这类事情的发生。
####重排何时发生
- ####添加或删除可见的 DOM 元素
- ####元素位置改变
- ####元素尺寸改变(因为边距,填充,边框宽度,宽度,高度等属性改变)
- ####内容改变,例如,文本改变或图片被另一个不同尺寸的所替代
- ####最初的页面渲染
- ####浏览器窗口改变尺寸
重绘和重排可能代价非常昂贵,因此一个好的提高程序影响速度的策略就是减少此类操作的发生。为了减少发生次数,应该合并多次对DOM和样式的修改,然后一次处理掉。改变样式可以使用cssText属性实现。
###第四章 算法和流程控制
对大多数编程语言而言,代码执行时间大部分消耗在循环中在一系列编程模式中,循环是最常用的模式之一,因此也是提高性能必须关注的地区之一。
####四种循环类型
- ####标准for循环
- ####while循环
- ####do-while循环
- ####for-in循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22//for循环
for (var count = 0; count < 10; count++) {
//循环主体
}
//while循环
var count = 0;
while (count < 10) {
//循环主体
count++
}
//do-while循环
var count = 0;
do {
//循环主体
} while (count++ < 10);
//for-in循环
for (var prop in object) {
//循环主体
}
不断引发循环性能争论的源头是循环类型的选择。在JavaScript提供的四种循环类型中,只有for-in循环比其他三种明显要慢。因此除非你的确需要迭代一个属性数量未知的对象,否则应避免使用for-in循环。
####减少迭代的工作量
不言而喻,如果一次循环迭代需要较长时间来执行,那么多次循环将需要更长时间。限制在循环体内进行耗时操作的数量是一个加快循环的好方法。
####减少迭代次数
即使是循环体中最快的代码累计迭代上千次也会慢下来,因此减少迭代次数能获得更加显著的性能提升。最广为人知的限制循环迭代次数的模式称作达夫设备。
达夫设备是一个循环体展开技术,在一次迭代中实际上执行了多次迭代操作。Jeff Greenberg 被认为是将达夫循环从原始的 C 实现移植到 JavaScript 中的第一人。一个典型的实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//credit: Jeff Greenberg
var iterations = Math.floor(items.length / 8),
startAt = items.length % 8,
i = 0;
do {
switch(startAt){
case 0: process(items[i++]);
case 7: process(items[i++]);
case 6: process(items[i++]);
case 5: process(items[i++]);
case 4: process(items[i++]);
case 3: process(items[i++]);
case 2: process(items[i++]);
case 1: process(items[i++]);
}
startAt = 0;
} while (--iterations);
达夫设备背后的基本理念是:每次循环中最多可8次调用process()函数。循环迭代次数为元素总数除以8。因为总数不一定是8的整数倍,所以startAt变量存放余数,指出第一次循环中应当执行多少次process()。比方说现在有12个元素,那么第一次循环将调用process()4次,第二次循环调用process()8次,用2次循环代替了12次循环。
此算法一个稍快的版本取消了switch表达式,将余数处理与主循环分开:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//credit: Jeff Greenberg
var i = items.length % 8;
while(i){
process(items[i--]);
}
i = Math.floor(items.length / 8);
while(i){
process(items[i--]);
process(items[i--]);
process(items[i--]);
process(items[i--]);
process(items[i--]);
process(items[i--]);
process(items[i--]);
process(items[i--]);
}
我读懂了作者的意思,却没看懂作者的代码,自己改了一下通过了测试1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20var items = 'abcdefghijklmnopqrstuvwxyz';
var iterations = Math.floor(items.length / 8),
startAt = items.length % 8,
i = 0;
function process (argument) {
console.log(argument);
}
while(startAt--){
process(items[i++]);
}
while(iterations--){
process(items[i++]);
process(items[i++]);
process(items[i++]);
process(items[i++]);
process(items[i++]);
process(items[i++]);
process(items[i++]);
process(items[i++]);
}
####条件语句
使用if-else或者switch的流行理论是基于测试条件的数量:条件数量较大,倾向于使用switch而不是if-else。这通常归结到代码的易读性。这种观点认为,如果条件较少时,if-else容易阅读,而条件较多时switch更容易阅读。
大多数情况下switch表达式比if-else更快,但只有当条件体数量很大时才明显更快。两者间的主要性能区别在于:当条件体增加时,if-else性能负担增加的程度比switch更多。因此,我们的自然倾向认为条件体较少时应使用if-else而条件体较多时应使用switch表达式,如果从性能方面考虑也是正确的。
一般来说,if-else适用于判断两个离散的值或者判断几个不同的值域。如果判断多于两个离散值,switch表达式将是更理想的选择。
####优化if-else
优化 if-else 的目标总是最小化找到正确分支之前所判断条件体的数量。最简单的优化方法是将最常见的条件体放在首位。考虑下面的例子:1
2
3
4
5
6
7if (value < 5) {
//do something
} else if (value > 5 && value < 10) {
//do something
} else {
//do something
}
这段代码只有当value值经常小于5时才是最优的。如果value经常大于等于10,那么在进入正确分支之前,必须两次运算条件体,导致表达式的平均时间提高。if-else中的条件体应当总是按照从最大概率到最小概率的顺序排列,以保证理论运行速度最快。
另外一种减少条件判断数量的方法是将if-else组织成一系列嵌套的if-else表达式。使用一个单独的一长串的if-else通常导致运行缓慢,因为每个条件体都要被计算。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23if (value == 0){
return result0;
} else if (value == 1){
return result1;
} else if (value == 2){
return result2;
} else if (value == 3){
return result3;
} else if (value == 4){
return result4;
} else if (value == 5){
return result5;
} else if (value == 6){
return result6;
} else if (value == 7){
return result7;
} else if (value == 8){
return result8;
} else if (value == 9){
return result9;
} else {
return result10;
}
在这个if-else表达式中,所计算条件体的最大数目是10。如果假设value的值在0到10之间均匀分布,那么会增加平均运行时间。为了减少条件判断的数量,此代码可重写为一系列嵌套的if-else表达式,例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35if (value < 6) {
if (value < 3) {
if (value == 0) {
return result0;
} else if (value == 1) {
return result1;
} else {
return result2;
}
} else {
if (value == 3) {
return result3;
} else if (value == 4) {
return result4;
} else {
return result5;
}
}
} else {
if (value < 8) {
if (value == 6) {
return result6;
} else {
return result7;
}
} else {
if (value == 8) {
return result8;
} else if (value == 9) {
return result9;
} else {
return result10;
}
}
}
在重写的if-else表达式中,每次抵达正确分支时最多通过四个条件判断。它使用二分搜索法将值域分成了一系列区间,然后逐步缩小范围。当数值范围分布在0到10时,此代码的平均运行时间大约是前面那个版本的一半。此方法适用于需要测试大量数值的情况(相对离散值来说switch更合适)。
####查表法(不是查水表:)
有些情况下要避免使用if-else或switch。当有大量离散值需要测试时,if-else和switch都比使用查表法要慢得多。在JavaScript中查表法可使用数组或者普通对象实现,查表法访问数据比if-else或者switch更快。
与if-else和switch相比,查表法不仅非常快,而且当需要测试的离散值数量非常大时,也有助于保持代码的可读性。例如,当 switch 表达式很大时就变得很笨重,诸如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24switch (value) {
case 0:
return result0;
case 1:
return result1;
case 2:
return result2;
case 3:
return result3;
case 4:
return result4;
case 5:
return result5;
case 6:
return result6;
case 7:
return result7;
case 8:
return result8;
case 9:
return result9;
default:
return result10;
}
switch表达式代码所占的空间可能与它的重要性不成比例。整个结构可以用一个数组查表替代:1
2
3
4//定义一个包含所有result的数组
var results = [result0, result1, result2, result3, result4, result5, result6, result7, result8, result9, result10];
//返回正确的result
return results[value];
当使用查表法时,必须完全消除所有条件判断。操作转换成一个数组项查询或者一个对象成员查询。使用查表法的一个主要优点是:由于没有条件判断,当候选值数量增加时,很少,甚至没有增加额外的性能开销。
查表法最常用于一个键和一个值形成逻辑映射的领域(如前面的例子)。一个switch表达式更适合于每个键需要一个独特的动作,或者一系列动作的场合。
###第五章 字符串和正则表达式
####字符串连接
字符串连接表现出惊人的性能紧张。通常一个任务通过一个循环,向字符串末尾不断地添加内容,来创建一个字符串(例如,创建一个HTML表或者一个XML文档),但此类处理在一些浏览器上表现糟糕而遭人痛恨。
当连接少量字符串时,所有这些函数都很快,临时使用的话,可选择最熟悉的使用。当合并字符串的长度和数量增加之后,有些函数开始显示出自己的威力。
(+)和(+=)加和加等于操作
这些操作符提供了连接字符串的最简单方法,事实上,除IE7和它之前的所有现代浏览器都对此优化得很好,所以你不需要寻找其他方法。然而,有些技术可以最大限度地提高这些操作的效率。
首先,看一个例子。这是连接字符串的常用方法:1
str += "one" + "two";
此代码执行时,发生四个步骤:
- ####内存中创建了一个临时字符串。
- ####临时字符串的值被赋予“onetwo”。
- ####临时字符串与 str 的值进行连接。
- ####结果赋予 str。
这基本上就是浏览器完成这一任务的过程。
下面的代码通过两个离散表达式直接将内容附加在str上避免了临时字符串(上面列表中第1步和第2步)。在大多数浏览器上这样做可加快10%-40%:1
2str += "one";
str += "two";
更进一步1
str = str + "one" + "two";
这就避免了使用临时字符串,因为赋值表达式开头以str为基础,一次追加一个字符串,从左至右依次连接。如果改变连接顺序(例如,str = "one" + str + "two"),你会失去这种优化。这与浏览器合并字符串时分配内存的方法有关。除IE以外,浏览器尝试扩展表达式左端字符串的内存,然后简单地将第二个字符串拷贝到它的尾部(如下图)。如果在一个循环中,基本字符串位于最左端,就可以避免多次复制一个越来越大的基本字符串。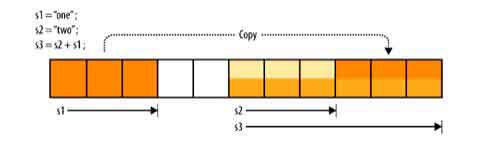
这些技术并不适用于IE。它们几乎没有任何作用,在IE8上甚至比IE7和早期版本更慢。这与IE执行连接操作的机制有关。
####正则表达式优化
简单说说正则表达式工作原理
第一步:编译
当你创建了一个正则表达式对象之后(使用一个正则表达式直接量或者RegExp构造器),浏览器检查你的模板有没有错误,然后将它转换成一个本机代码例程,用于执行匹配工作。如果你将正则表达式赋给一个变量,你可以避免重复执行此步骤。
第二步:设置起始位置
当一个正则表达式投入使用时,首先要确定目标字符串中开始搜索的位置。它是字符串的起始位置,或者由正则表达式的 lastIndex 属性指定,但是当它从第四步返回到这里的时候(因为尝试匹配失败),此位置将位于最后一次尝试起始位置推后一个字符的位置上。
第三步:匹配每个正则表达式的字元
正则表达式一旦找好起始位置,它将一个一个地扫描目标文本和正则表达式模板。当一个特定字元匹配失败时,正则表达式将试图回溯到扫描之前的位置上,然后进入正则表达式其他可能的路径上。
第四步:匹配成功或失败
如果在字符串的当前位置上发现一个完全匹配,那么正则表达式宣布成功。如果正则表达式的所有可能路径都尝试过了,但是没有成功地匹配,那么正则表达式引擎回到第二步,从字符串的下一个字符重新尝试。只有字符串中的每个字符(以及最后一个字符后面的位置)都经历了这样的过程之后,还没有成功匹配,那么正则表达式就宣布彻底失败。
###第六章 快速响应的用户界面
这章直接写小结吧
JavaScript和用户界面更新在同一个进程内运行,同一时刻只有其中一个可以运行。这意味着当JavaScript代码正在运行时,用户界面不能响应输入,反之亦然。有效地管理UI线程就是要确保JavaScript不能运行太长时间,以免影响用户体验。最后,请牢记如下几点:
- ####JavaScript运行时间不应该超过100毫秒。过长的运行时间导致UI更新出现可察觉的延迟,从而对整体用户体验产生负面影响。
- ####JavaScript运行期间,浏览器响应用户交互的行为存在差异。无论如何,JavaScript长时间运行将导致用户体验混乱和脱节。
- ####定时器可用于安排代码推迟执行,它使得你可以将长运行脚本分解成一系列较小的任务。
- ####网页工人线程是新式浏览器才支持的特性,它允许你在UI线程之外运行JavaScript代码而避免锁定UI。
网页应用程序越复杂,积极主动地管理UI线程就越显得重要。没有什么JavaScript代码可以重要到允许影响用户体验的程度。
###第七章 Ajax
Ajax是高性能JavaScript的基石。它可以通过延迟下载大量资源使页面加载更快。它通过在客户端和服务器之间异步传送数据,避免页面集体加载。它还用于在一次HTTP请求中获取整个页面的资源。通过选择正确的传输技术和最有效的数据格式,你可以显著改善用户与网站之间的互动。
####数据传输
Ajax,在它最基本的层面,是一种与服务器通讯而不重载当前页面的方法,数据可从服务器获得或发送给服务器。有多种不同的方法构造这种通讯通道,每种方法都有自己的优势和限制。
#####数据格式
在考虑数据传输技术时,你必须考虑这些因素:功能集,兼容性,性能,和方向(发给服务器或者从服务器接收)。在考虑数据格式时,唯一需要比较的尺度的就是速度。
没有哪种数据格式会始终比其他格式更好。根据传送什么数据、用于页面上什么目的,某种格式可能下载更快,另一种格式可能解析更快。
XML
Ajax开始变得流行起来它选择了XML数据格式。有很多事情是围绕着它做的:极端的互通性(服务器端和客户端都能够良好支持),格式严格,易于验证。那时JSON还没有正式作为交换格式,几乎所有的服务器端语言都有操作XML的库。
这里是用XML编码的用户列表的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<?xml version="1.0" encoding='UTF-8'?>
<users total="4">
<user id="1">
<username>alice</username>
<realname>Alice Smith</realname>
<email>alice@alicesmith.com</email>
</user>
<user id="2">
<username>bob</username>
<realname>Bob Jones</realname>
<email>bob@bobjones.com</email>
</user>
<user id="3">
<username>carol</username>
<realname>Carol Williams</realname>
<email>carol@carolwilliams.com</email>
</user>
<user id="4">
<username>dave</username>
<realname>Dave Johnson</realname>
<email>dave@davejohnson.com</email>
</user>
</users>
与其他格式相比,XML极其冗长。每个离散的数据片断需要大量结构,所以有效数据的比例非常低。而且XML语法有些轻微模糊。
JSON
JSON是一种使用JavaScript对象和数组直接量编写的轻量级并易于解析的数据格式,它由Douglas Crockford创立并推广开来。下例是用 JSON 书写的用户列表:1
2
3
4
5
6[
{"id":1, "username":"alice", "realname": "Alice Smith", "email":"alice@alicesmith.com"},
{"id":2, "username":"bob", "realname": "Bob Jones", "email":"bob@bobjones.com"},
{"id":3, "username":"carol", "realname": "Carol Williams","email":"carol@carolwilliams.com"},
{"id":4, "username":"dave", "realname": "Dave Johnson", "email":"dave@davejohnson.com"}
]
用户表示为一个对象,用户列表成为一个数组,与JavaScript中其他数组或对象的写法相同。这意味着如果它被包装在一个回调函数中,JSON 数据可称为能够运行的JavaScript代码。在JavaScript中解析JSON可简单地使用():1
2
3function parseJSON(responseText) {
return ('(' + responseText + ')');
}
关于JSON和eval需要注意
在代码中使用eval是很危险的,特别使用它来解析第三方的JSON数据(其中可能包含恶意代码)时,尽可能使用JSON.parse()方法解析字符串本身。
正如 XML 那样,它也可以提炼成一个更简单的版本。这种情况下,我们可将名字缩短(尽管可读性变差):1
2
3
4
5
6[
{ "i": 1, "u": "alice", "r": "Alice Smith", "e": "alice@alicesmith.com" },
{ "i": 2, "u": "bob", "r": "Bob Jones", "e": "bob@bobjones.com" },
{ "i": 3, "u": "carol", "r": "Carol Williams", "e": "carol@carolwilliams.com" },
{ "i": 4, "u": "dave", "r": "Dave Johnson", "e": "dave@davejohnson.com" }
]
还有更过分的:1
2
3
4
5
6[
[ 1, "alice", "Alice Smith", "alice@alicesmith.com" ],
[ 2, "bob", "Bob Jones", "bob@bobjones.com" ],
[ 3, "carol", "Carol Williams", "carol@carolwilliams.com" ],
[ 4, "dave", "Dave Johnson", "dave@davejohnson.com" ]
]
JSON-P
事实上JSON可被本地执行有几个重要的性能影响。当使用XHR时JSON数据作为一个字符串返回。该字符串使用()转换为一个本地对象。然而,当使用动态脚本标签插入时,JSON数据被视为另一个JavaScript文件并作为本地码执行。为做到这一点,数据必须被包装在回调函数之中。这就是所谓的“JSON填充”或JSON-P。下面是我们用JSON-P格式书写的用户列表:1
2
3
4
5
6parseJSON([
{"id":1, "username":"alice", "realname":"Alice Smith", "email":"alice@alicesmith.com"},
{"id":2, "username":"bob", "realname":"Bob Jones", "email":"bob@bobjones.com"},
{"id":3, "username":"carol", "realname":"Carol Williams", "email":"carol@carolwilliams.com"},
{"id":4, "username":"dave", "realname":"Dave Johnson", "email":"dave@davejohnson.com"}
]);
JSON-P的产生
- ####一个众所周知的问题,Ajax直接请求普通文件存在跨域无权限访问的问题,甭管你是静态页面、动态网页、web服务、WCF,只要是跨域请求,一律不准;
- ####不过我们又发现,Web页面上调用js文件时则不受是否跨域的影响(不仅如此,我们还发现凡是拥有
src这个属性的标签都拥有跨域的能力,比如<script>、<img>、<iframe>); - ####于是可以判断,当前阶段如果想通过纯web端(ActiveX控件、服务端代理、属于未来的HTML5之Websocket等方式不算)跨域访问数据就只有一种可能,那就是在远程服务器上设法把数据装进js格式的文件里,供客户端调用和进一步处理;
- ####恰巧我们已经知道有一种叫做JSON的纯字符数据格式可以简洁的描述复杂数据,更妙的是JSON还被js原生支持,所以在客户端几乎可以随心所欲的处理这种格式的数据;
- ####这样子解决方案就呼之欲出了,Web客户端通过与调用脚本一模一样的方式,来调用跨域服务器上动态生成的js格式文件(一般以JSON为后缀),显而易见,服务器之所以要动态生成JSON文件,目的就在于把客户端需要的数据装入进去。
- ####客户端在对JSON文件调用成功之后,也就获得了自己所需的数据,剩下的就是按照自己需求进行处理和展现了,这种获取远程数据的方式看起来非常像AJAX,但其实并不一样。
- ####为了便于客户端使用数据,逐渐形成了一种非正式传输协议,人们把它称作JSON-P,该协议的一个要点就是允许用户传递一个callback参数给服务端,然后服务端返回数据时会将这个
callback参数作为函数名来包裹住JSON数据,这样客户端就可以随意定制自己的函数来自动处理返回数据了。
1 | <!Doctype html> |
我们看到调用的url中传递了一个code参数,告诉服务器我要查的是CA1998次航班的信息,而callback参数则告诉服务器,我的本地回调函数叫做flightHandler,所以请把查询结果传入这个函数中进行调用。OK,服务器很聪明,这个叫做flightResult.aspx的页面生成了一段这样的代码提供给jsonp.html(服务端的实现这里就不演示了,与你选用的语言无关,说到底就是拼接字符串):1
2
3
4
5flightHandler({
"code": "CA1998",
"price": 1780,
"tickets": 5
});
Ajax和JSON-P这两种技术在调用方式上“看起来”很像,目的也一样,都是请求一个url,然后把服务器返回的数据进行处理,因此jQuery和Ext等框架都把JSON-P作为Ajax的一种形式进行了封装。
但Ajax和JSON-P其实本质上是不同的东西。Ajax的核心是通过XmlHttpRequest获取非本页内容,而JSON-P的核心则是动态添加<script>标签来调用服务器提供的js脚本。
jQuery在处理JSON-P类型的Ajax时(虽然jQuery也把JSON-P归入了Ajax,但其实它们真的不是一回事儿),自动帮你生成回调函数并把数据取出来供success属性方法来调用。
HTML
通常你所请求的数据以HTML返回并显示在页面上。JavaScript能够比较快地将一个大数据结构转化为简单的HTML,但是服务器完成同样工作更快。一种技术考虑是在服务器端构建整个HTML然后传递给客户端,JavaScript只是简单地下载它然后放入innerHTML。
此技术的问题在于,HTML是一种详细的数据格式,比XML更加冗长。在数据本身的最外层,可有嵌套的HTML标签,每个都具有ID,类,和其他属性。HTML格式可能比实际数据占用更多的空间,尽管可通过尽量少用标签和属性缓解这一问题。
自定义格式
最理想的数据格式只包含必要的结构,使你能够分解出每个字段。你可以自定义一种格式只是简单地用一个分隔符将数据连结起来。
####数据格式总结
总的来说越轻量级的格式越好,最好是JSON和字符分隔的自定义格式。如果数据集很大或者解析时间成问题,那么就使用这两种格式之一:
XML相比JSON有许多优点。这种格式小得多,在总响应报文中,结构占用的空间更小,数据占用的更多。特别是数据包含数组而不是对象时。JSON与大多数服务器端语言的编解码库之间有着很好的互操作性。它在客户端的解析工作微不足道,使你可以将更多写代码的时间放在其他数据处理上。对网页开发者来说最重要的是,它是表现最好的格式之一,即因为在线传输相对较小,也因为解析十分之快。JSON是高性能Ajax的基石,特别是使用动态脚本标签插入时。
最快的Ajax请求就是你不要用它。可以缓存数据来减少Ajax请求。
###第八章 编程实践
关于这章,直接写小结吧
JavaScript提出了一些独特的性能挑战,关系到你组织代码的方法。网页应用变得越来越高级,包含的JavaScript代码越来越多,出现了一些模式和反模式。请牢记以下编程经验:
- ####通过避免使用eval()和Function()构造器避免二次评估。此外,给setTimeout()和setInterval()传递函数参数而不是字符串参数。
- ####创建新对象和数组时使用对象直接量和数组直接量。它们比非直接量形式创建和初始化更快。
- ####避免重复进行相同工作。当需要检测浏览器时,使用延迟加载或条件预加载。
- ####当执行数学远算时,考虑使用位操作,它直接在数字底层进行操作。
- ####原生方法总是比 JavaScript 写的东西要快。尽量使用原生方法。
###第九章 创建并部署高性能JavaScript应用程序
关于这章,还是直接写小结吧
- ####合并JavaScript文件,减少HTTP请求的数量
- ####使用YUI压缩器紧凑处理JavaScript文件
- ####以压缩形式提供JavaScript文件(gzip编码)
- ####通过设置HTTP响应报文头使JavaScript文件可缓存,通过向文件名附加时间戳解决缓存问题
- ####使用内容传递网络(CDN)提供JavaScript文件,CDN不仅可以提高性能,它还可以为你管理压缩和缓存
###第十章 工具
关于这章,还是直接写小结吧
- ####使用网络分析器找出加载脚本和其它页面资源的瓶颈所在,这有助于决定哪些脚本需要延迟加载,或者进行进一步分析。
- ####传统的智慧告诉我们应尽量减少HTTP请求的数量,尽量延迟加载脚本以使页面渲染速度更快,向用户提供更好的整体体验。
- ####使用性能分析器找出脚本运行时速度慢的部分,检查每个函数所花费的时间,以及函数被调用的次数,通过调用栈自身提供的一些线索来找出哪些地方应当努力优化。
- ####虽然花费时间和调用次数通常是数据中最有价值的点,还是应当仔细察看函数的调用过程,可能发现其它优化方法。
好了,花了近两天时间把这本《高性能JavaScript》总结了,大致把我觉得重要的和有用的给拣出来了。
